Data Streaming Journey: Moving from MySQL to BigQuery with Kafka Connect and Debezium
In the ever-evolving landscape of data management and analytics, the need for real-time, scalable, and efficient data streaming solutions has become paramount. In this data-driven era, organizations are seeking ways to seamlessly transfer and synchronize data between diverse databases and cloud platforms. This article embarks on a journey into the realm of data streaming, exploring how to establish a robust pipeline for streaming data between MySQL and BigQuery using Kafka and Debezium. Let’s start 🚀 !

1. Why Use Debezium and Kafka Connect?
When it comes to streaming data from Relational database (Postresql, MySQL..) to BigQuery or any relatioal or anaytics database, the combination of Debezium and Kafka Connect stands out as a powerful and agnostic solution. Numerous alternatives exist within Google Cloud Platform (GCP), such as utilizing the managed service DataStream or integrating Debezium with Pubsub and Dataflow. However, I aim to initiate this series of articles with agnostic, standard, and open-source tools and below more arguments 😊 :
Real-Time Change Data Capture (CDC):
Change Data Capture (CDC) is a technique for capturing and recording all the changes made to a database over time. This allows for real-time data replication, making it easy to keep multiple systems in sync. CDC does this by detecting row-level changes in database source tables, which are characterized as “Insert,” “Update,” and “Delete” events. CDC then notifies other systems or services that rely on the same data.
Debezium specializes in CDC; it’s an open-source platform that allows you to easily stream changes from your MySQL database to other systems using CDC. It works by reading MySQL binlog to capture data changes in a transactional manner, so you can be sure that you’re always working with the most up-to-date data. This granular level of data capture allows for accurate and timely streaming of updates, inserts, and deletes, ensuring that the destination system stays synchronized with the source
Fault Tolerance and Scalability:
Kafka, at its core, is designed for fault tolerance and scalability. The distributed nature of Kafka ensures that even in the face of node failures, data streams remain available and consistent. Kafka Connect further enhances this by providing a scalable framework for managing connectors, making it well-suited for handling large volumes of data and adapting to the evolving needs of a data streaming journey.
Seamless Integration with Kafka:
Kafka Connect, an integral part of the Apache Kafka ecosystem, acts as the bridge between Kafka and external data sources or sinks. Its modular connectors facilitate the easy integration of various systems. Debezium, as a specialized connector for databases, integrates seamlessly with Kafka Connect, forming a robust foundation for building scalable and fault-tolerant data pipelines.
Simplified Configuration and Deployment:
Debezium and Kafka Connect make configuration and deployment straightforward. With Debezium’s connectors handling the intricacies of database-specific changes, and Kafka Connect managing the flow of data, the setup process becomes streamlined. This simplicity translates to reduced development time and lower maintenance overhead, allowing organizations to focus on deriving value from their streaming data.
In summary, the combination of Debezium and Kafka Connect offers a compelling solution for streaming data from MySQL to BigQuery. It empowers organizations with real-time data synchronization, fault tolerance, and scalability, providing the foundation for building a data streaming journey that aligns with the demands of the modern data landscape.
2. Prerequisite and Assumption
To start syncing data from MySQL to BigQuery we will need following components:
- Apache Zookeeper: ZooKeeper is used in distributed systems for service synchronization and as a naming registry. When working with Apache Kafka, ZooKeeper is primarily used to track the status of nodes in the Kafka cluster and maintain a list of Kafka topics and messages.
- Apache Kafka.
- Kafka Connect.
- Debezium service with MySQL connector and Google BigQuery connector plugins.
- MySQL database: we will setup a local SQL database for the demo but feel free to replace it by a managed or any SQL database.
3. High level architecture:
In order to implement real-time CDC-based change replication from MySQL to Bigquery, we will implement the following architecture ⤵️:

The Bigquery Sink connector streams CDC events stored in Kafka topic and sent by Debezium, automatically transforms events to the DML SQL statements (INSERT / UPDATE / DELETE), and executes SQL statements in the target database in the order they were created. It also supports bulk load into columnar databases. The same setup of CDC can be used to connect the following databases (sources) :
- Microsoft SQL Server
- MongoDB
- MySQL
- Oracle
- IBM DB2
- PostgreSQL
To the following destinations:
- File storage (S3, GCS..)
- Relational database.
- Snowflake.
- Amazon Redshift.
- Google BigQuery.
- Azure Synapse Analytics.
- ElasticSearch
4. Setup required services
1. Let’s start with creating a new directory. Open Terminal and run:
$ mkdir kafka-connect-tuto && cd kafka-connect-tuto2. Create a plugins directory:
$ mkdir plugins3. Download Debezium mysql plugin:
$ wget https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/2.1.1.Final/debezium-connector-mysql-2.1.1.Final-plugin.tar.gz -O mysql-plugin.tar.gz$ tar -xzf mysql-plugin.tar.gz -C plugins4. Download BigQuery plugin and put the contents into your plugins directory (in this tutorial we are using version v2.4.3). Now your plugins directory should look like this:
$ ls pluginsdebezium-connector-mysql wepay-kafka-connect-bigquery-2.4.3In order to setup kafka and zookeeper, we can either use the Kafka server available in GCP marketplace or use docker-compose. In this article, I will go with the second option for cost purpose.
Below our docker-compose file to deploy all the required services locally:
version: '2'
services:
zookeeper:
container_name: zookeeper
image: quay.io/debezium/zookeeper:2.1
ports:
- 2181:2181
environment:
- ALLOW_ANONYMOUS_LOGIN=yes
kafka:
container_name: kafka
image: quay.io/debezium/kafka:2.1
ports:
- 9092:9092
links:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
mysql:
container_name: mysql
image: quay.io/debezium/example-mysql:2.1
ports:
- 3306:3306
environment:
- MYSQL_ROOT_PASSWORD=debezium
- MYSQL_USER=mysqluser
- MYSQL_PASSWORD=mysqlpw
connect:
container_name: connect
image: quay.io/debezium/connect-base:2.1
volumes:
- ./plugins:/kafka/connect
ports:
- 8083:8083
links:
- kafka
- mysql
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
debezium-ui:
image: quay.io/debezium/debezium-ui:2.2
ports:
- 8090:8080
links:
- connect
environment:
- KAFKA_CONNECT_URIS=http://connect:8083Let’s explain the different components:
- We first create a zookeeper service with basic configuration. In this, I kept ALLOW_ANONYMOUS_LOGIN environment variable as yes to connect with unauthorized users. Click on zookeeper configuration for more details.
- Then we have to create a Kafka service. ZOOKEEPER_CONNECT is used to access zookeeper service from Kafka. As we are using docker-compose you can give service name and expose the port of zookeeper container directly. E.g zookeeper:2181
- Deploy a MySQL database server that includes an example
inventorydatabase that includes several tables that are pre-populated with data. The Debezium MySQL connector will capture changes that occur in the sample tables and transmit the change event records to an Apache Kafka topic. - After creating Kafka service and our database server, we need to create Kafka Connect distributed service. It will help in importing/exporting data to Kafka and runs connectors to implement custom logic for interacting with an external system.
- Debezium UI: it allows users to set up and operate connectors more easily using a web interface.
6. Let’s start the services:
After runningdocker-compose up , we will have our debezium UI available locally through the port 8090, but without any connector.

You can check if Debezium is running with Kafka Connect API :
$ curl -i -X GET -H "Accept:application/json" localhost:8083/connectors
We can also verify whether MySQL is running with the example database “inventory”. You can check for the available tables by running:
docker exec -it mysql mysql -uroot -pdebezium -D inventory -e "SHOW TABLES;"
You can perform a query to a table to see its content:
$ docker exec -it mysql mysql -uroot -pdebezium -D inventory -e "SELECT * FROM customers;"
5. Configure Debezium to start syncing MySQL to Kafka
MySQL has a binary log (binlog) that records all operations in the order in which they are committed to the database. This includes changes to table schemas as well as changes to the data in tables. MySQL uses the binlog for replication and recovery. The Debezium MySQL connector reads the binlog, produces change events for row-level INSERT, UPDATE, and DELETE operations, and emits the change events to Kafka topics. Client applications read those Kafka topics.
The Debezium MySQL connector includes the following features:
- At least once delivery : The connector guarantees that records are delivered at least once to the Kafka topic. If a fault occurs (for example, if there are network connectivity issues), or the connector restarts, you may see some duplicate records in the Kafka topic.
- Supports one task: The Debezium PostgreSQL Source connector supports running only one task.
- Automatic topic creation: The connector will create the internal database history Kafka topic if it doesn’t exist.
Assuming that the Debezium is up and running, we will be configuring a connector to the MySQL database using Kafka Connect REST API. In this article we will create Debezium connectors REST API, so make sure either curl or Postman is installed in your development box. The alternative to REST API for creating Debezium connectors is a Debezium UI, created earlier.
1. Create a new file (“mysql-connector.json”) with these configurations:
{
"name": "mysql-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "root",
"database.password": "debezium",
"database.server.id": "184054",
"topic.prefix": "debezium",
"database.include.list": "inventory",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092",
"schema.history.internal.kafka.topic": "schemahistory.inventory"
}
}As you saw, we need to provide a name for our connector, its class (io.debezium.connector.mysql.MySqlConnector), specify the connection parameters to our database, and finally, specify which database to include in our CDC process (in this case, 'inventory'). Additionally, we have the option to watch/monitor only a specific table instead of the entire database by using the attribute 'table.include.list'.
To register the connector, run the following command :
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @mysql-connector.json
You can also navigate to the UI to check that connector is created:

Debezium stores CDC events in a separate topic for each table. For example, the CDC events for the table customers will be stored in a Kafka topic database_server_name.inventory.customers.
To check the topics created by Debezium connector, run :
docker exec -it kafka bash bin/kafka-topics.sh --list --bootstrap-server kafka:9092
Now let’s check the debezium CDC events on a specific table :
docker exec -it kafka bash bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic debezium.inventory.addresses --from-beginning
We see a list of dictionaries containing all the operations performed on a specific table. The most important attribute to check is “op”. It’s a mandatory string that describes the type of operation. In an update event value, the op field value is u, signifying that this row changed because of an update, c for create, t for truncate and d for delete.
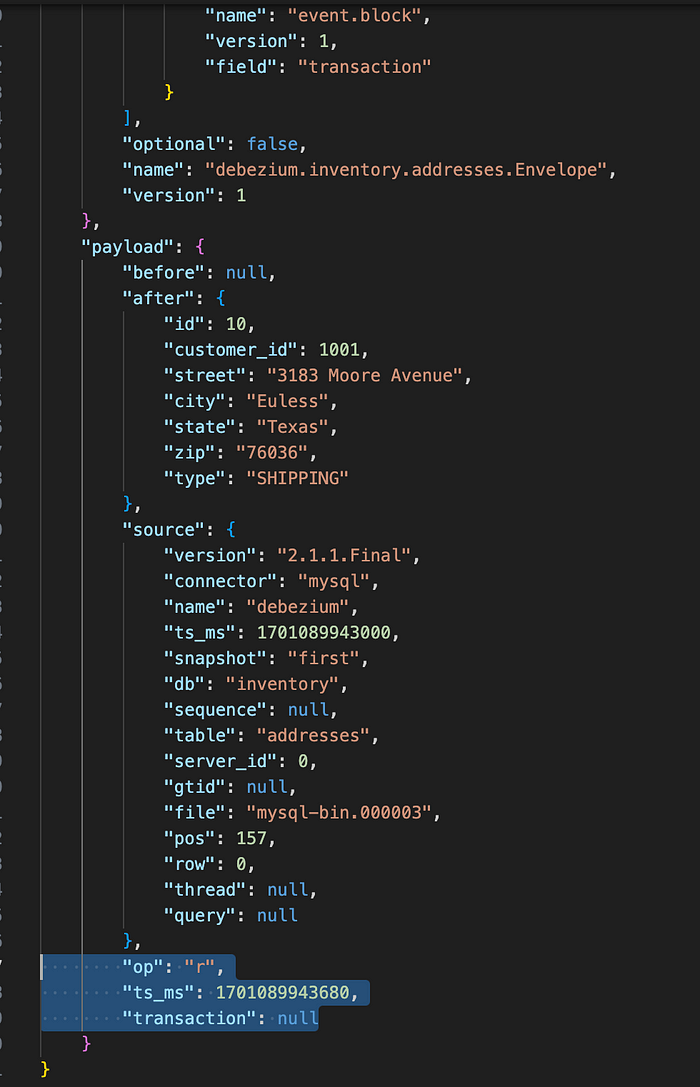
For more information on Debezium events, see this Debezium documentation.
6. Syncing data to Google BigQuery
Now, we will register a Kafka connector to sink data based on the events streamed into the previously discussed Kafka topics. We will achieve this by using a JSON configuration file named “bigquery-connector.json’”:
{
"name": "inventory-connector-bigquery",
"config": {
"connector.class": "com.wepay.kafka.connect.bigquery.BigQuerySinkConnector",
"tasks.max": "1",
"consumer.auto.offset.reset": "earliest",
"topics.regex": "debezium.inventory.*",
"sanitizeTopics": "true",
"autoCreateTables": "true",
"keyfile": "/bigquery-keyfile.json",
"schemaRetriever": "com.wepay.kafka.connect.bigquery.retrieve.IdentitySchemaRetriever",
"project": "my-gcp-project-id",
"defaultDataset": "kafka_dataset",
"allBQFieldsNullable": true,
"allowNewBigQueryFields": true,
"transforms": "regexTopicRename,extractAfterData",
"transforms.regexTopicRename.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.regexTopicRename.regex": "debezium.inventory.(.*)",
"transforms.regexTopicRename.replacement": "$1",
"transforms.extractAfterData.type": "io.debezium.transforms.ExtractNewRecordState"
}
}Make sure to replace the dataset “defaultDataset” with the name of the desired dataset in your Bigquery project. If your remove this field, Kafka connector will keep the same name of the source database. You need also to provide a service account key to the connector with Bigquery/DataEditor role on the target dataset. If your kafka connect is deployed in kubernetes or a compute engine, you can remove the attribute “keyfile” and use directly workload identity.
Before submitting the connector, I will create a empty dataset in bigquery :

Now let’s register our Bigquery sink:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" http://localhost:8083/connectors/ -d @bigquery-connector.json
Just after a few seconds, our SQL database is replicated to BigQuery, great 🎉 !!

Now, let’s explore the power of CDC !
Our “customers” table contains initially 4 rows in MySQL and Bigquery:

Let’s add a new record to the source table :
docker exec -it mysql mysql -uroot -pdebezium -D inventory -e "INSERT INTO customers VALUES(1111, \"kafka_product\", \"This is Mohamed from kafka connect\",\"mohamed@kafkaconnect.com\");"I see the update in MySQL table:

After just one second, you will see that a new entry has automatically synced to BigQuery :

You can check as well that a CDC “create” event was published into the kafka topic “inventory.customers” :

And that’s it ! We have a full pipeline to synchronize, in near real-time, data from MySQL database to Bigquery. As I mentioned earlier, we can replace Bigquery by ElasticSearch, Postgresql, Redshift… you just need to check the available sink connector in Kafka Connect, or develop a new one 😎.
Conclusion
You should now have a clear understanding of the benefits of syncing data from MySQL to BigQuery using Debezium’s capability to capture changes at the database level, coupled with Kafka Connect’s role in facilitating smooth integration with Kafka and external systems. As a reminder, it’s important to test and monitor the pipeline to ensure that data is being synced as expected and to troubleshoot any issues that may arise.
In my next article about data streaming , I will explain how to replace Bigquery kafka connector by Pubsub and Dataflow.
Please let me know if you have any feedback or questions !
